Difference between revisions of "Runtime Systems"
Pthomadakis (talk | contribs) (→PREMA 2.0) |
Pthomadakis (talk | contribs) (→Decoupled CDT3D) |
||
| (26 intermediate revisions by 3 users not shown) | |||
| Line 1: | Line 1: | ||
| − | + | == PREMA 2.0 == | |
| − | |||
| − | + | === Decoupled CDT3D === | |
| + | In this experiment, we use our in-house mesh generation software ''CTD3D'' to test the performance of PREMA with ILB in a real application. We test our software with 4 core allocations of 640, 1280, 3200 and 5600 cores and compare its performance with the respective MPI version of the code. In the first two figures, the initial mesh used consists of about 30 million elements and we create 4.5k subdomains in total. In addition to the comparison with MPI we can see the performance strong scaling between the 640 and 1280 core allocations of PREMA. For the 3.2k and 5.6k core allocations we use an initial mesh with 110 million elements from which we create 26.9k subdomains. There is no MPI version for the 3.2k core allocation because the program took too long to terminate and was stopped prematurely. | ||
| + | {| | ||
| + | |- | ||
| + | |[[File:MPI_CDT3D_640.png|680px|link=]] | ||
| + | |[[File:PREMA_CDT3D_640.png|680px|link=]] | ||
| + | |- | ||
| + | | colspan="2" | ''' Figure 7. Per worker load comparison between MPI and PREMA with ILB on 640 cores. MPI uses 640 as workers while PREMA uses 620 for workers plus 20 for communication. Initial mesh: 30mil elements, 4.5k subdomains''' | ||
| + | |} | ||
| + | |||
| + | {| | ||
| + | |- | ||
| + | |[[File:MPI_CDT3D_1280.png|680px|link=]] | ||
| + | |[[File:PREMA_CDT3D_1280.png|680px|link=]] | ||
| + | |- | ||
| + | | colspan="2" | ''' Figure 8. Per worker load comparison between MPI and PREMA with ILB on 1280 cores. MPI uses 1280 as workers while PREMA uses 1240 for workers plus 40 for communication. Initial mesh: same as fig.7''' | ||
| + | |} | ||
| + | |||
| + | {| | ||
| + | |- | ||
| + | |[[File:PREMA_CDT3D_3200.png|680px|link=]] | ||
| + | |- | ||
| + | | colspan="2" | ''' Figure 9. Per worker load in PREMA with ILB on 3200 cores. 3000 cores for workers plus 200 for communication. Initial mesh: 110mil elements, 26.9k subdomains''' | ||
| + | |} | ||
| + | |||
| + | {| | ||
| + | |- | ||
| + | |[[File:MPI_CDT3D_5600.png|680px|link=]] | ||
| + | |[[File:PREMA_CDT3D_5600.png|680px|link=]] | ||
| + | |- | ||
| + | | colspan="2" | ''' Figure 10. Per worker load comparison between MPI and PREMA with ILB on 5600 cores. MPI uses 5600 as workers while PREMA uses 5250 for workers plus 350 for communication. Initial mesh: same as fig.9''' | ||
| + | |} | ||
| + | |||
| + | {| class="wikitable" style="margin-left: auto; margin-right: auto; border: none;" | ||
| + | |+ Performance breakdown and comparison with MPI | ||
| + | |- | ||
| + | ! rowspan="2"| #cores | ||
| + | ! colspan="3"| Load balance overhead (sec) | ||
| + | ! colspan="2"| Time to initialize (sec) | ||
| + | ! colspan="2"|Min refinement time (sec) | ||
| + | ! colspan="2"| Max refinement time (sec) | ||
| + | |||
| + | |- | ||
| + | ! Max || Min || Avg || ILB || MPI || ILB || MPI || ILB || MPI | ||
| + | |||
| + | |- | ||
| + | |640 || 7.0 || 0.00004 || 0.18 || 0.47 || 0.32 || 80.4 || 7.7 || 197.12 || 338.6 | ||
| + | |- | ||
| + | |1280 || 0.82 || 0.0001 || 0.05 || 1.79 || 0.92 || 31.12 || 4.6 || 162.2 || 307.2 | ||
| + | |||
| + | |- | ||
| + | |3200 || 37.9 || 0.004 || 0.64 || 3.11 || - || 86.1 || - || 325.2 || - | ||
| + | |||
| + | |- | ||
| + | |5600 || 29.5 || 0.002 || 0.48 || 0.49 || 18.2 || 51.17 || 5.7 || 252.6 || 511.9 | ||
| + | |||
| + | |} | ||
| + | |||
| + | === Synthetic Benchmark === | ||
| + | To examine the performance of our runtime system itself without the difficulties caused by the complexity of the applications running on top of it, we have developed a synthetic benchmark. The benchmark begins by dispersing work units to available processors, computation is the invoked via PREMA's messaging mechanism. Once computations of a data object are complete, a notification is sent back to the root processor. The application terminates once all notifications have been received. The number of subdomains per available core is set to 10, the weights of the individual workers are assigned to two categories, light and heavy. The average time of a heavyweight unit is 2.5 times the time of a lightweight one and 20% of the work units are assigned to the heavy category. In the graphs below, the load of different work units of the same worker is depicted with different colors. This helps to make the heavy tasks easily recognizable and to show how the work units have migrated among the workers in the case of PREMA. Figures 1-3 show performance for PREMA using 1 core for communication per 32 cores and figures 4-6 using 1 per 16 cores. | ||
| + | {| | ||
| + | |- | ||
| + | |[[File:RTS_MPI_320.png|680px|link=]] | ||
| + | |[[File:RTS_PREMA_320.png|680px|link=]] | ||
| + | |- | ||
| + | |colspan="2" style="text-align: center;" | '''Figure 1. Per worker load comparison between MPI and PREMA with ILB on 320 cores. MPI uses 320 as workers while PREMA uses 310 for workers plus 10 for communication''' | ||
| + | |} | ||
| + | |||
| + | {| | ||
| + | |- | ||
| + | |[[File:RTS_MPI_640.png|680px|link=]] | ||
| + | |[[File:RTS_PREMA_640.png|680px|link=]] | ||
| + | |- | ||
| + | |colspan="2" style="text-align: center;" | '''Figure 2. Per worker load comparison between MPI and PREMA with ILB on 640 cores. MPI uses 640 as workers while PREMA uses 620 for workers plus 20 for communication''' | ||
| + | |} | ||
| + | |||
| + | {| | ||
| + | |- | ||
| + | |[[File:RTS_MPI_1280.png|680px|link=]] | ||
| + | |[[File:RTS_PREMA_1280.png|680px|link=]] | ||
| + | |- | ||
| + | |colspan="2" style="text-align: center;" | '''Figure 3. Per worker load comparison between MPI and PREMA with ILB on 1280 cores. MPI uses 1280 as workers while PREMA uses 1240 for workers plus 40 for communication''' | ||
| + | |} | ||
| + | |||
| + | {| | ||
| + | |- | ||
| + | |[[File:RTS_MPI_3200.png|680px|link=]] | ||
| + | |[[File:RTS_PREMA_3200.png|680px|link=]] | ||
| + | |- | ||
| + | |colspan="2" style="text-align: center;" | '''Figure 4. Per worker load comparison between MPI and PREMA with ILB on 3200 cores. MPI uses 3200 as workers while PREMA uses 3000 for workers plus 200 for communication''' | ||
| + | |} | ||
| + | |||
| + | {| | ||
| + | |- | ||
| + | |[[File:RTS_MPI_4800.png|680px|link=]] | ||
| + | |[[File:RTS_PREMA_4800.png|680px|link=]] | ||
| + | |- | ||
| + | |colspan="2" style="text-align: center;" | '''Figure 5. Per worker load comparison between MPI and PREMA with ILB on 4800 cores. MPI uses 4800 as workers while PREMA uses 4500 for workers plus 300 for communication''' | ||
| + | |} | ||
| + | |||
| + | {| | ||
| + | |- | ||
| + | |[[File:RTS_MPI_5600.png|680px|link=]] | ||
| + | |[[File:RTS_PREMA_5600.png|680px|link=]] | ||
| + | |- | ||
| + | |colspan="2" style="text-align: center;" | '''Figure 6. Per worker load comparison between MPI and PREMA with ILB on 5600 cores. MPI uses 5600 as workers while PREMA uses 5250 for workers plus 350 for communication''' | ||
| + | |} | ||
| + | |||
| + | |||
| + | {| class="wikitable" style="margin-left: auto; margin-right: auto; border: none;" | ||
| + | |+ Performance breakdown and comparison with MPI | ||
| + | |- | ||
| + | ! rowspan="2"| #cores | ||
| + | ! colspan="3"| Load balance overhead (sec) | ||
| + | ! colspan="2"| Time to initialize (sec) | ||
| + | ! colspan="2"|Min refinement time (sec) | ||
| + | ! colspan="2"| Max refinement time (sec) | ||
| + | ! colspan="2"|Total time (sec) | ||
| + | |- | ||
| + | ! Max || Min || Avg || ILB || MPI || ILB || MPI || ILB || MPI || ILB || MPI | ||
| + | |- | ||
| + | |320 || 0.84 || 0.0001 || 0.07 || 0.83 || 1.28 || 464.8 || 324.9 || 494.4 || 681.8 || 495.5 || 683.2 | ||
| + | |||
| + | |- | ||
| + | |640 || 0.82 || 0.0001 || 0.05 || 1.39 || 0.97 || 464.1 || 321.4 || 495.1 || 687.1 || 496.8 || 692.7 | ||
| + | |||
| + | |- | ||
| + | |1280 || 0.76 || 0.0001 || 0.05 || 1.35 || 1.57 || 464.9 || 324.7 || 497.6 || 704.1 || 499.3 || 713.1 | ||
| + | |||
| + | |- | ||
| + | |3200 || 0.37 || 0.0002 || 0.05 || 2.81 || 2.31 || 480.7 || 322.1 || 515.2 || 691.9 || 520.5 || 717.2 | ||
| + | |||
| + | |- | ||
| + | |4800 || 0.35 || 0.0001 || 0.04 || 2.77 || 3.64 || 480.4 || 322.6 || 516.3 || 704.7 || 524.9 || 745.5 | ||
| + | |||
| + | |- | ||
| + | |5600 || 0.48 || 0.0003 || 0.04 || 3.36 || 5.75 || 479.2 || 310.6 || 515.9 || 717.8 || 526.4 || 770.1 | ||
| + | |||
| + | |} | ||
Latest revision as of 20:23, 19 June 2018
PREMA 2.0
Decoupled CDT3D
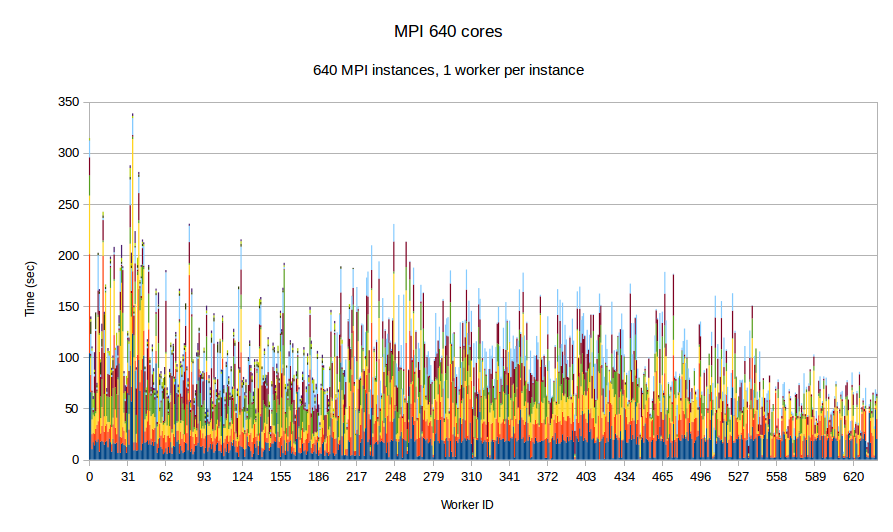
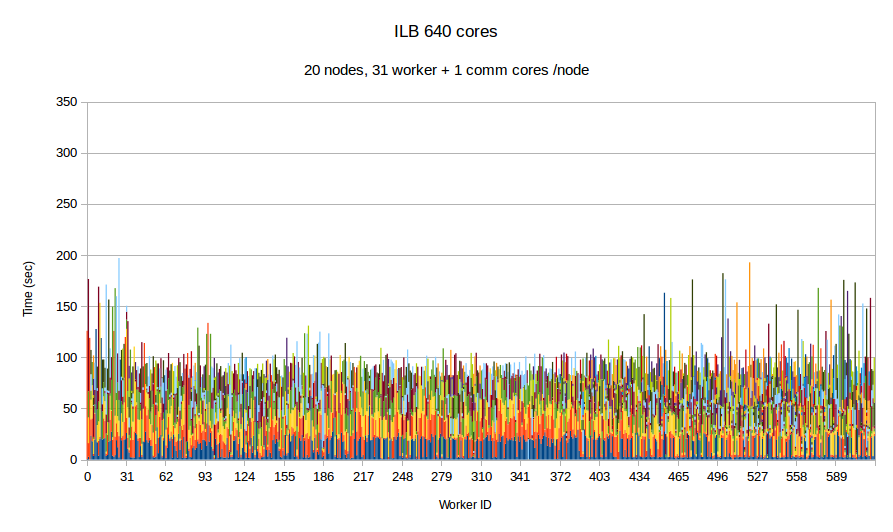
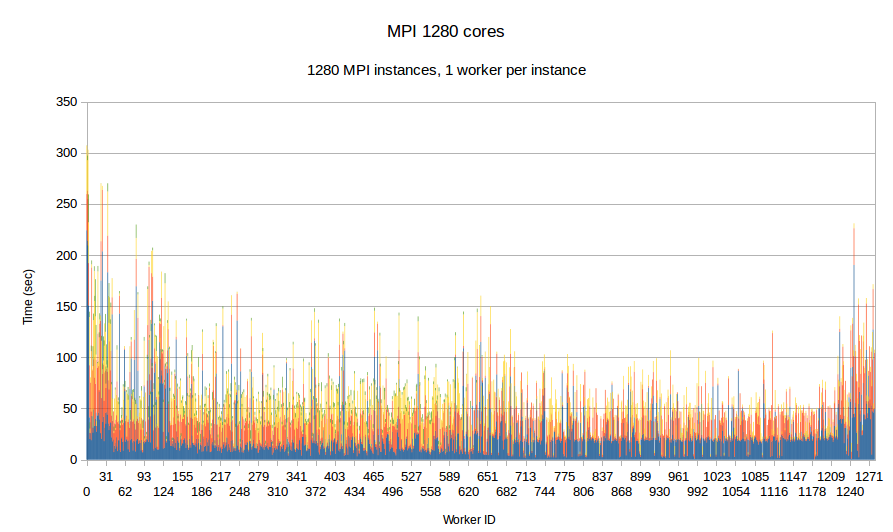
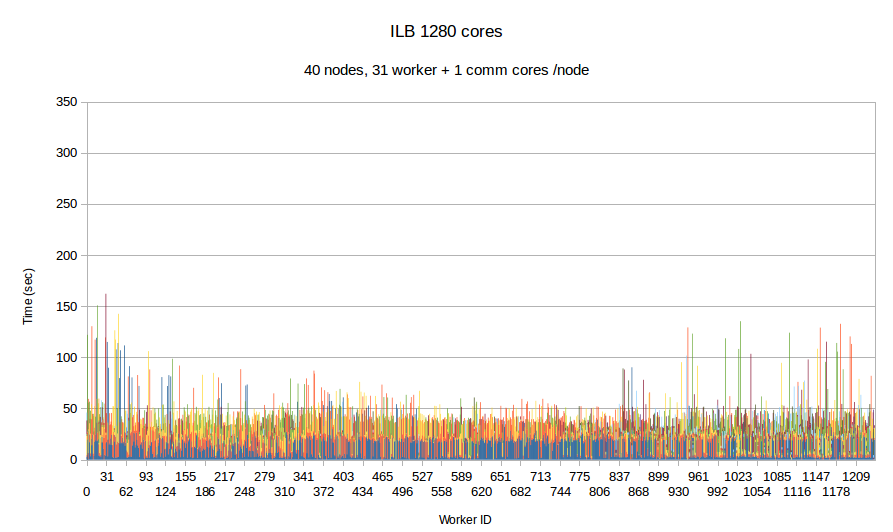
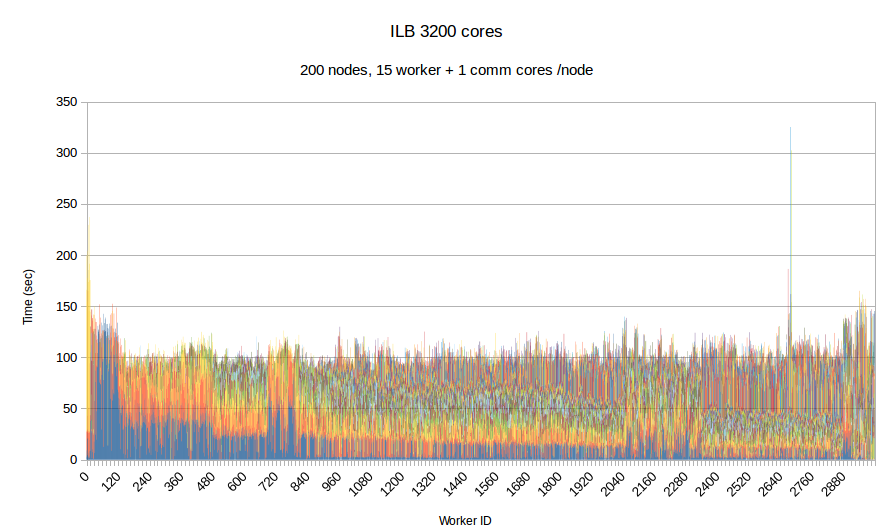
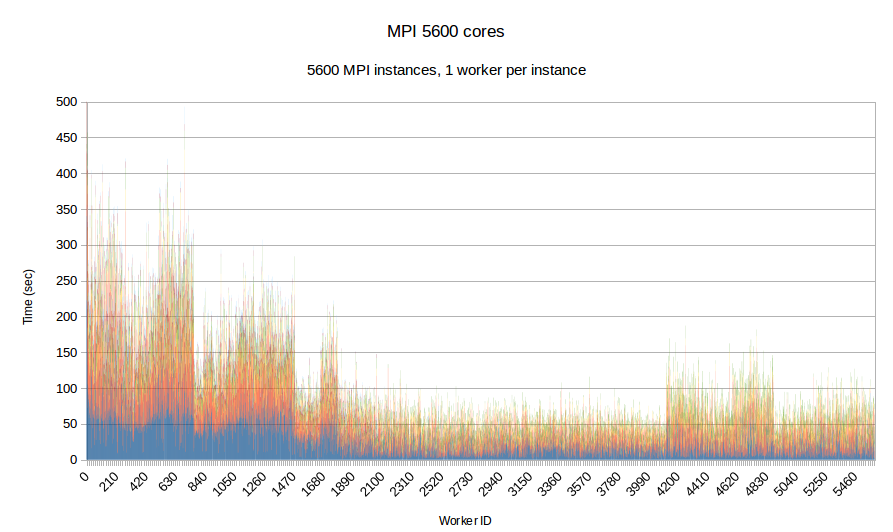
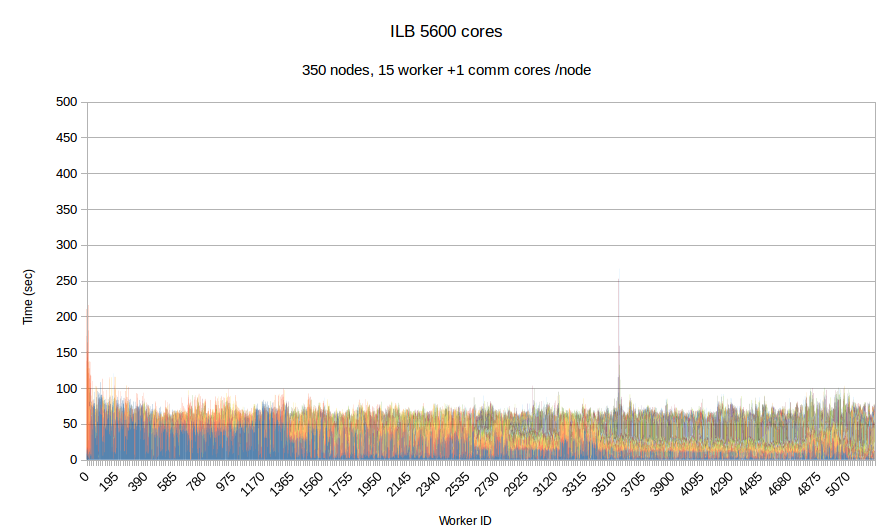
In this experiment, we use our in-house mesh generation software CTD3D to test the performance of PREMA with ILB in a real application. We test our software with 4 core allocations of 640, 1280, 3200 and 5600 cores and compare its performance with the respective MPI version of the code. In the first two figures, the initial mesh used consists of about 30 million elements and we create 4.5k subdomains in total. In addition to the comparison with MPI we can see the performance strong scaling between the 640 and 1280 core allocations of PREMA. For the 3.2k and 5.6k core allocations we use an initial mesh with 110 million elements from which we create 26.9k subdomains. There is no MPI version for the 3.2k core allocation because the program took too long to terminate and was stopped prematurely.
|
|
| Figure 7. Per worker load comparison between MPI and PREMA with ILB on 640 cores. MPI uses 640 as workers while PREMA uses 620 for workers plus 20 for communication. Initial mesh: 30mil elements, 4.5k subdomains | |
|
|
| Figure 8. Per worker load comparison between MPI and PREMA with ILB on 1280 cores. MPI uses 1280 as workers while PREMA uses 1240 for workers plus 40 for communication. Initial mesh: same as fig.7 | |
| |
| Figure 9. Per worker load in PREMA with ILB on 3200 cores. 3000 cores for workers plus 200 for communication. Initial mesh: 110mil elements, 26.9k subdomains | |
|
|
| Figure 10. Per worker load comparison between MPI and PREMA with ILB on 5600 cores. MPI uses 5600 as workers while PREMA uses 5250 for workers plus 350 for communication. Initial mesh: same as fig.9 | |
| #cores | Load balance overhead (sec) | Time to initialize (sec) | Min refinement time (sec) | Max refinement time (sec) | |||||
|---|---|---|---|---|---|---|---|---|---|
| Max | Min | Avg | ILB | MPI | ILB | MPI | ILB | MPI | |
| 640 | 7.0 | 0.00004 | 0.18 | 0.47 | 0.32 | 80.4 | 7.7 | 197.12 | 338.6 |
| 1280 | 0.82 | 0.0001 | 0.05 | 1.79 | 0.92 | 31.12 | 4.6 | 162.2 | 307.2 |
| 3200 | 37.9 | 0.004 | 0.64 | 3.11 | - | 86.1 | - | 325.2 | - |
| 5600 | 29.5 | 0.002 | 0.48 | 0.49 | 18.2 | 51.17 | 5.7 | 252.6 | 511.9 |
Synthetic Benchmark
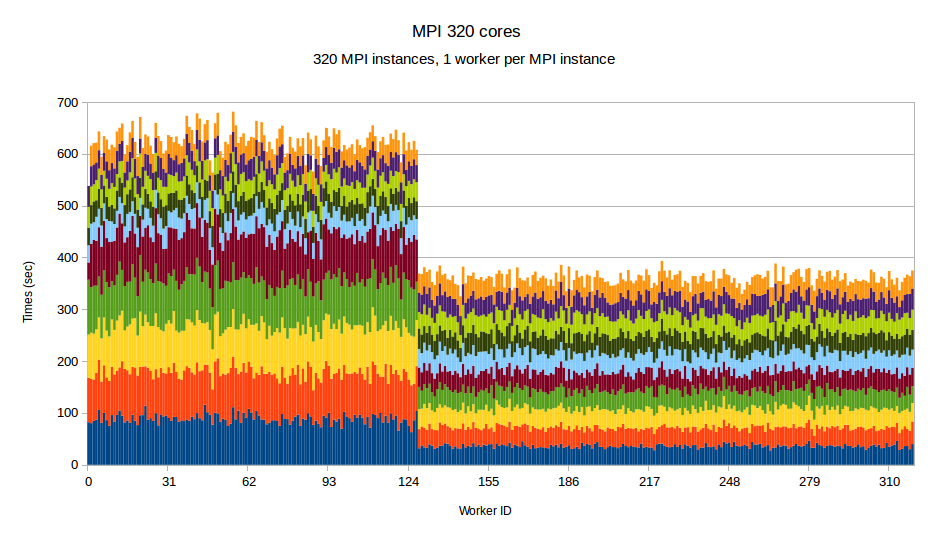
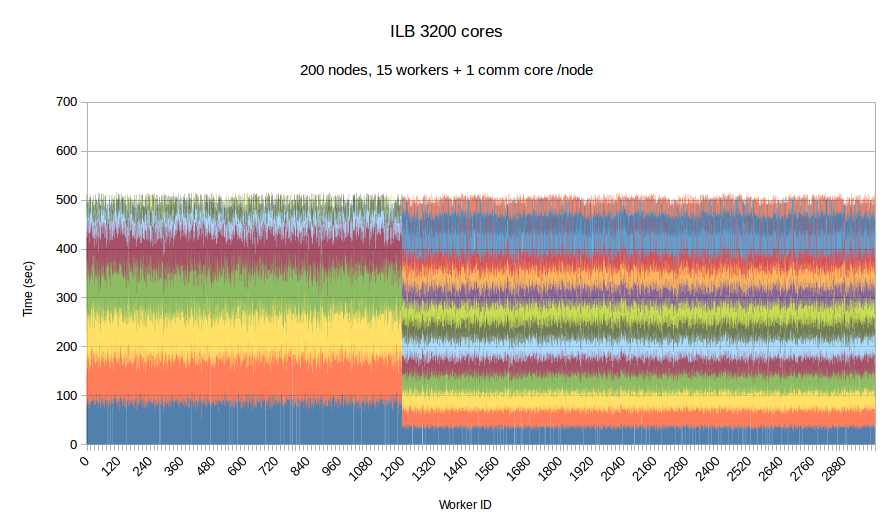
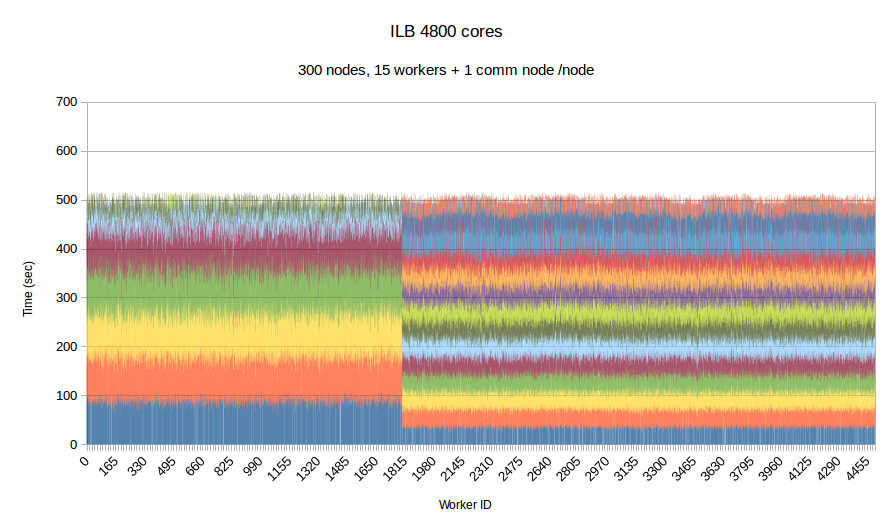
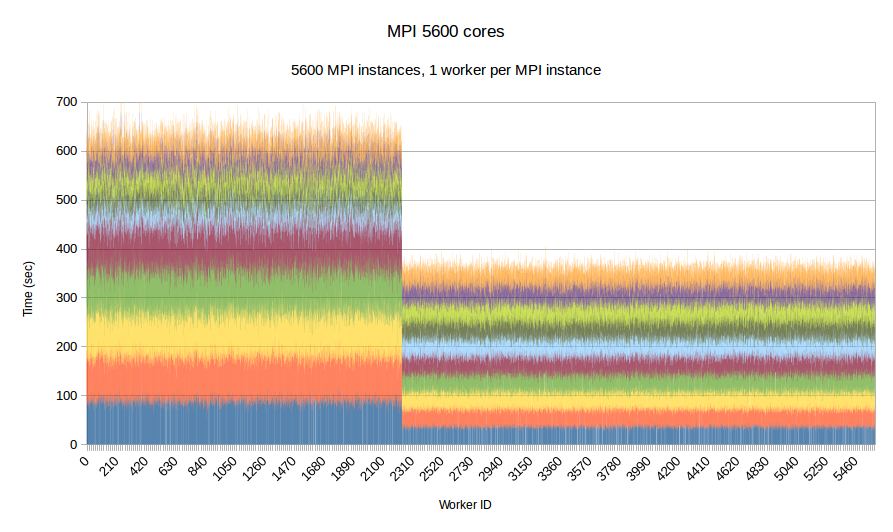
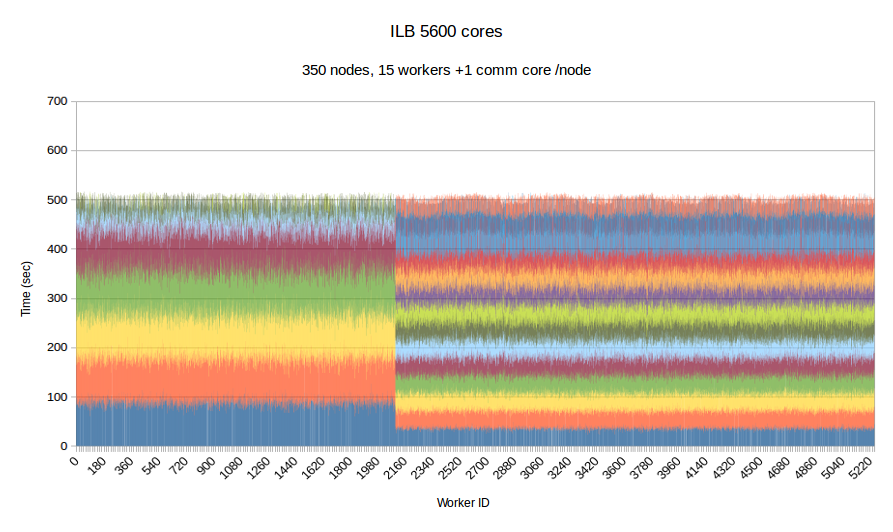
To examine the performance of our runtime system itself without the difficulties caused by the complexity of the applications running on top of it, we have developed a synthetic benchmark. The benchmark begins by dispersing work units to available processors, computation is the invoked via PREMA's messaging mechanism. Once computations of a data object are complete, a notification is sent back to the root processor. The application terminates once all notifications have been received. The number of subdomains per available core is set to 10, the weights of the individual workers are assigned to two categories, light and heavy. The average time of a heavyweight unit is 2.5 times the time of a lightweight one and 20% of the work units are assigned to the heavy category. In the graphs below, the load of different work units of the same worker is depicted with different colors. This helps to make the heavy tasks easily recognizable and to show how the work units have migrated among the workers in the case of PREMA. Figures 1-3 show performance for PREMA using 1 core for communication per 32 cores and figures 4-6 using 1 per 16 cores.
|
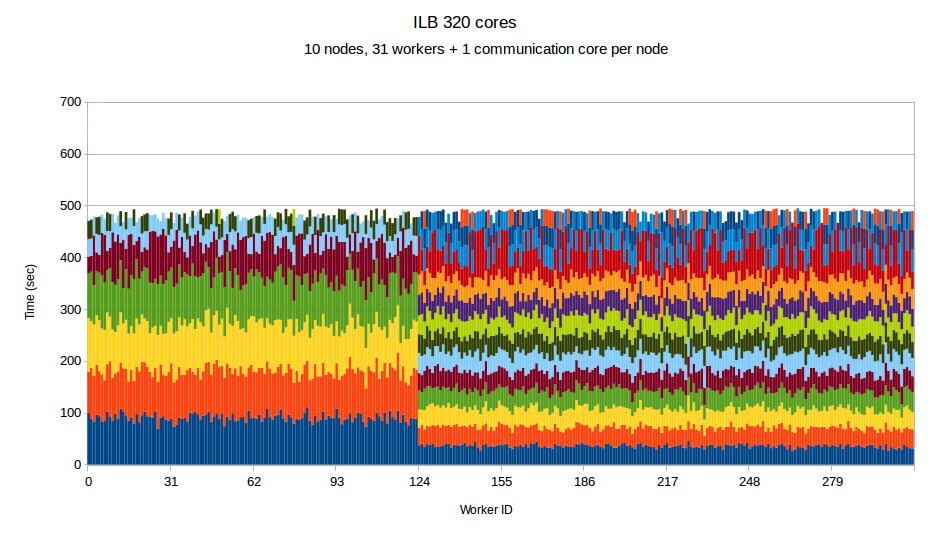
|
| Figure 1. Per worker load comparison between MPI and PREMA with ILB on 320 cores. MPI uses 320 as workers while PREMA uses 310 for workers plus 10 for communication | |
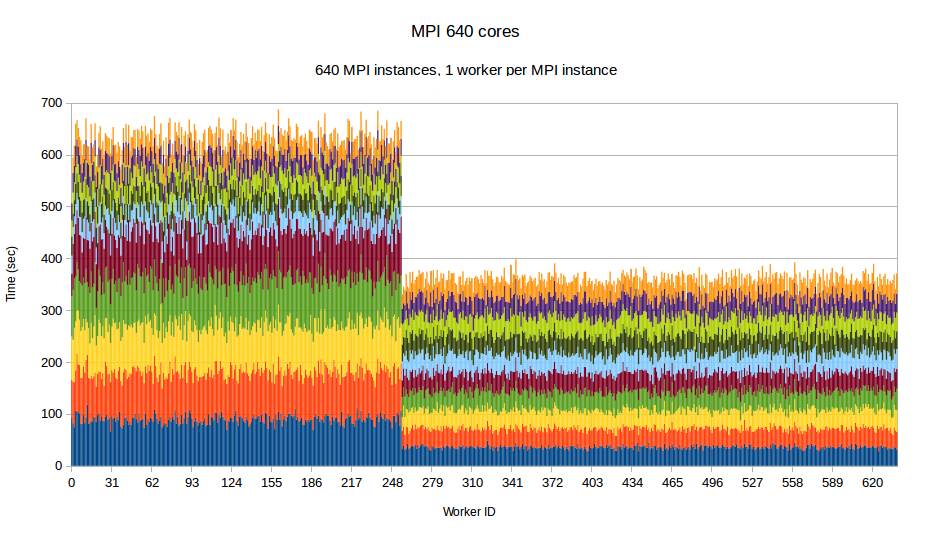
|
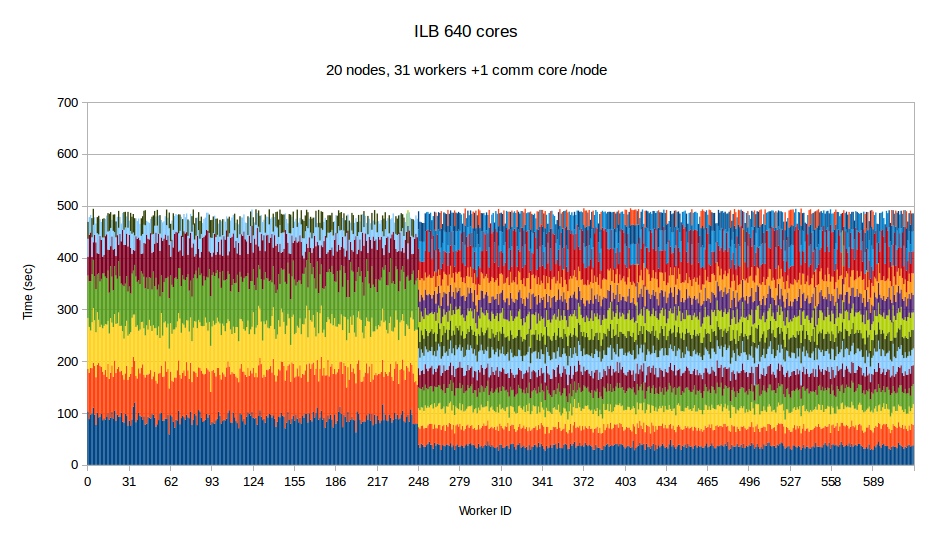
|
| Figure 2. Per worker load comparison between MPI and PREMA with ILB on 640 cores. MPI uses 640 as workers while PREMA uses 620 for workers plus 20 for communication | |
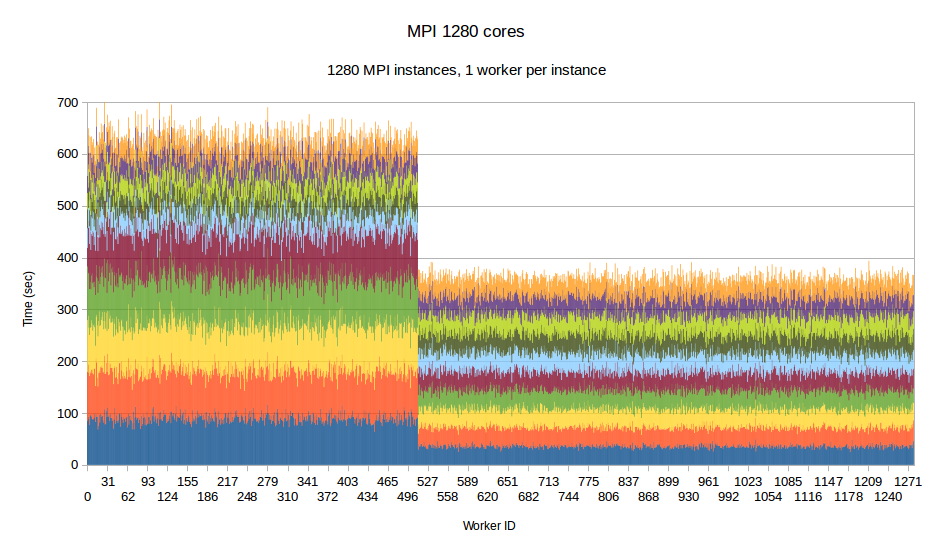
|
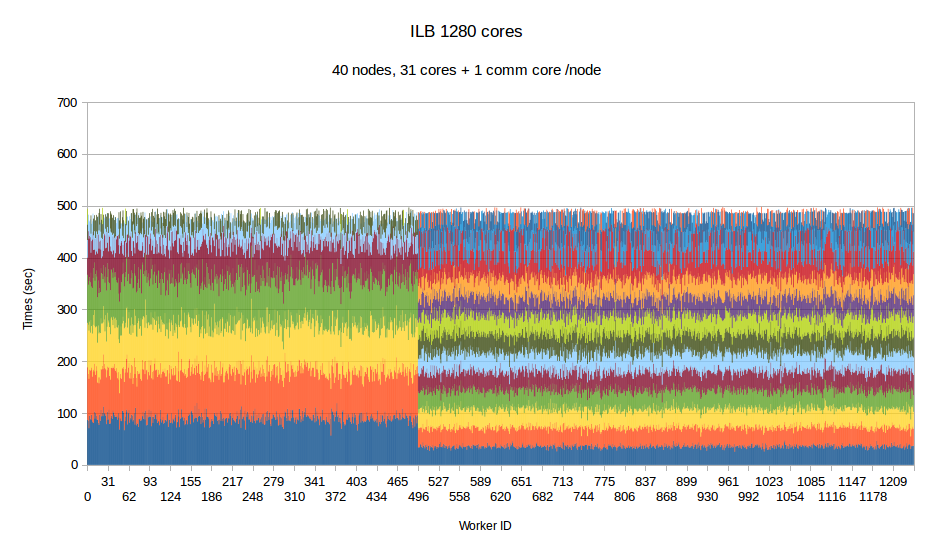
|
| Figure 3. Per worker load comparison between MPI and PREMA with ILB on 1280 cores. MPI uses 1280 as workers while PREMA uses 1240 for workers plus 40 for communication | |
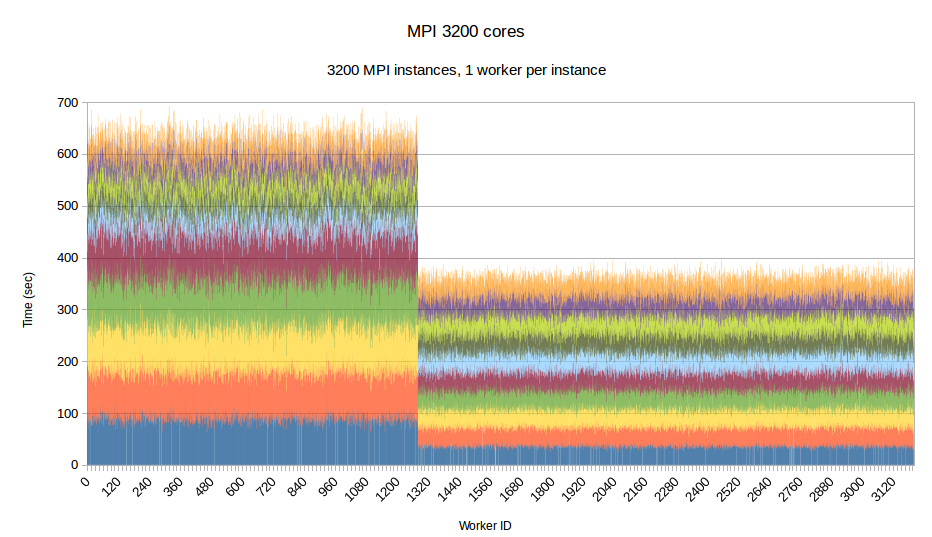
|
|
| Figure 4. Per worker load comparison between MPI and PREMA with ILB on 3200 cores. MPI uses 3200 as workers while PREMA uses 3000 for workers plus 200 for communication | |
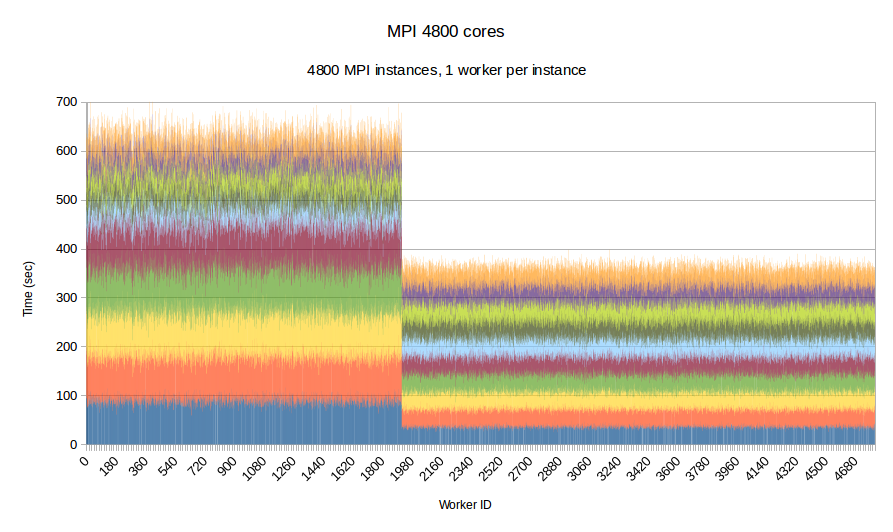
|
|
| Figure 5. Per worker load comparison between MPI and PREMA with ILB on 4800 cores. MPI uses 4800 as workers while PREMA uses 4500 for workers plus 300 for communication | |
|
|
| Figure 6. Per worker load comparison between MPI and PREMA with ILB on 5600 cores. MPI uses 5600 as workers while PREMA uses 5250 for workers plus 350 for communication | |
| #cores | Load balance overhead (sec) | Time to initialize (sec) | Min refinement time (sec) | Max refinement time (sec) | Total time (sec) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Max | Min | Avg | ILB | MPI | ILB | MPI | ILB | MPI | ILB | MPI | |
| 320 | 0.84 | 0.0001 | 0.07 | 0.83 | 1.28 | 464.8 | 324.9 | 494.4 | 681.8 | 495.5 | 683.2 |
| 640 | 0.82 | 0.0001 | 0.05 | 1.39 | 0.97 | 464.1 | 321.4 | 495.1 | 687.1 | 496.8 | 692.7 |
| 1280 | 0.76 | 0.0001 | 0.05 | 1.35 | 1.57 | 464.9 | 324.7 | 497.6 | 704.1 | 499.3 | 713.1 |
| 3200 | 0.37 | 0.0002 | 0.05 | 2.81 | 2.31 | 480.7 | 322.1 | 515.2 | 691.9 | 520.5 | 717.2 |
| 4800 | 0.35 | 0.0001 | 0.04 | 2.77 | 3.64 | 480.4 | 322.6 | 516.3 | 704.7 | 524.9 | 745.5 |
| 5600 | 0.48 | 0.0003 | 0.04 | 3.36 | 5.75 | 479.2 | 310.6 | 515.9 | 717.8 | 526.4 | 770.1 |